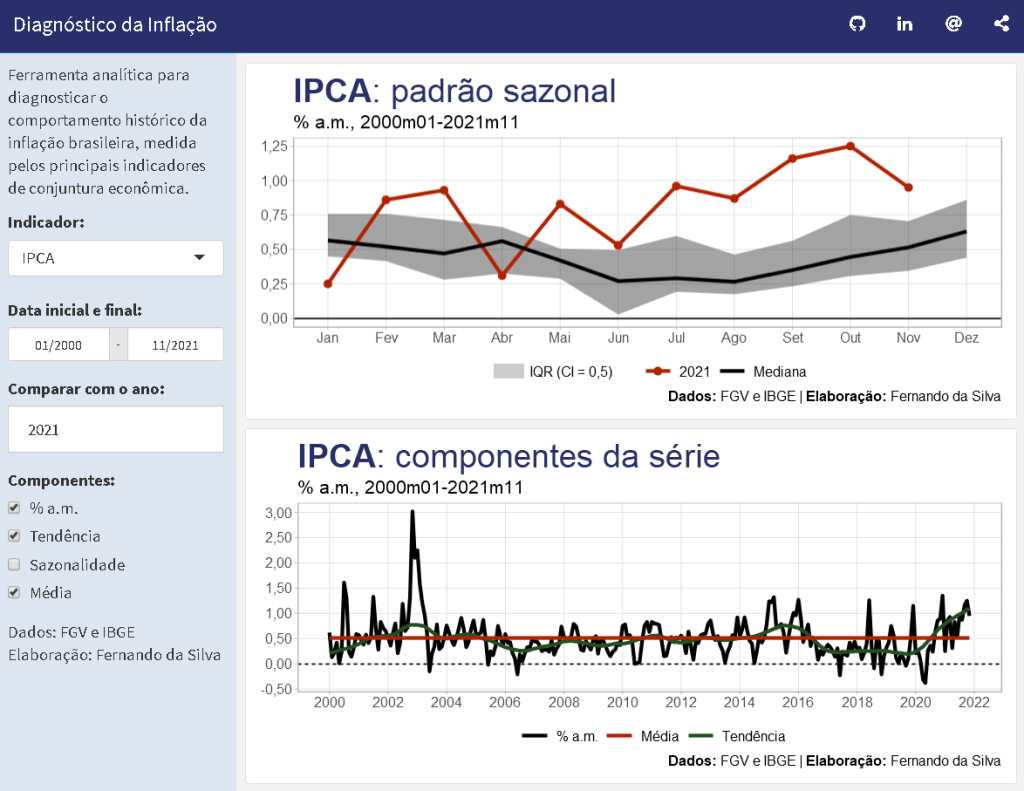
Quando o objetivo é analisar dados, é necessário utilizar as ferramentas adequadas para tornar os dados brutos em informação que seja útil. Para tal, uma dashboard pode ser o formato mais conveniente, dado seu poder de customização, compartilhamento e automatização. Nesse contexto, exploramos como exemplo a construção de uma dashboard simples aplicada à análise dos dados de inflação do Brasil, fazendo uso dos principais pacotes da linguagem R.
O objetivo deste exercício é construir uma dashboard dinâmica onde seja possível analisar o comportamento histórico dos principais indicadores para acompanhamento de conjuntura do tema inflação. Sendo assim, a dashboard deve dar autonomia para o usuário filtrar os indicadores, períodos e métricas de comparação de seu interesse, além de primar por uma apresentação visual limpa e agradável aos olhos. Nada melhor do que ter controle e facilidade no momento de analisar os dados, certo? Estes são os princípios dessa dashboard, apesar de ser um exemplo simples e didático.
Recursos da dashboard
Vamos resumir os principais recursos dessa dashboard de análise da inflação no Brasil, começando pelas medidas de inflação disponíveis, em % a.m.:
- IPCA (IBGE);
- INPC (IBGE);
- IGP-M (FGV);
- IGP-DI (FGV);
- IPC-Br (FGV).
Estes são apenas 5 dos principais indicadores acompanhados aqui no Brasil. Dentro da estrutura e layout da dashboard você poderia adicionar muitos outros (ou remover, o que preferir).
Além disso, a dashboard pode conter os seguintes recursos:
- Filtros de tempo (calendário de seleção de datas);
- Comparação de anos (campo para verificar sazonalidade de um ano específico) e;
- Botões para habilitar/desabilitar métricas (tendência, sazonalidade, média histórica da série, etc.).
Demonstração
Tudo isso viabiliza uma análise mais customizável e de fácil utilização pelo usuário final. Vale dizer também que com o R é possível automatizar completamente a dashboard, desde a extração dos dados direto na fonte (IBGE, FGV, etc.) até o deploy periódico para um serviço na nuvem, como o Shinyapps.
Agora chega de papo e vamos para a prática! Se quiser conferir o resultado final (completo), está aqui o link para a dashboard: https://schoulten.shinyapps.io/dash_inflation/
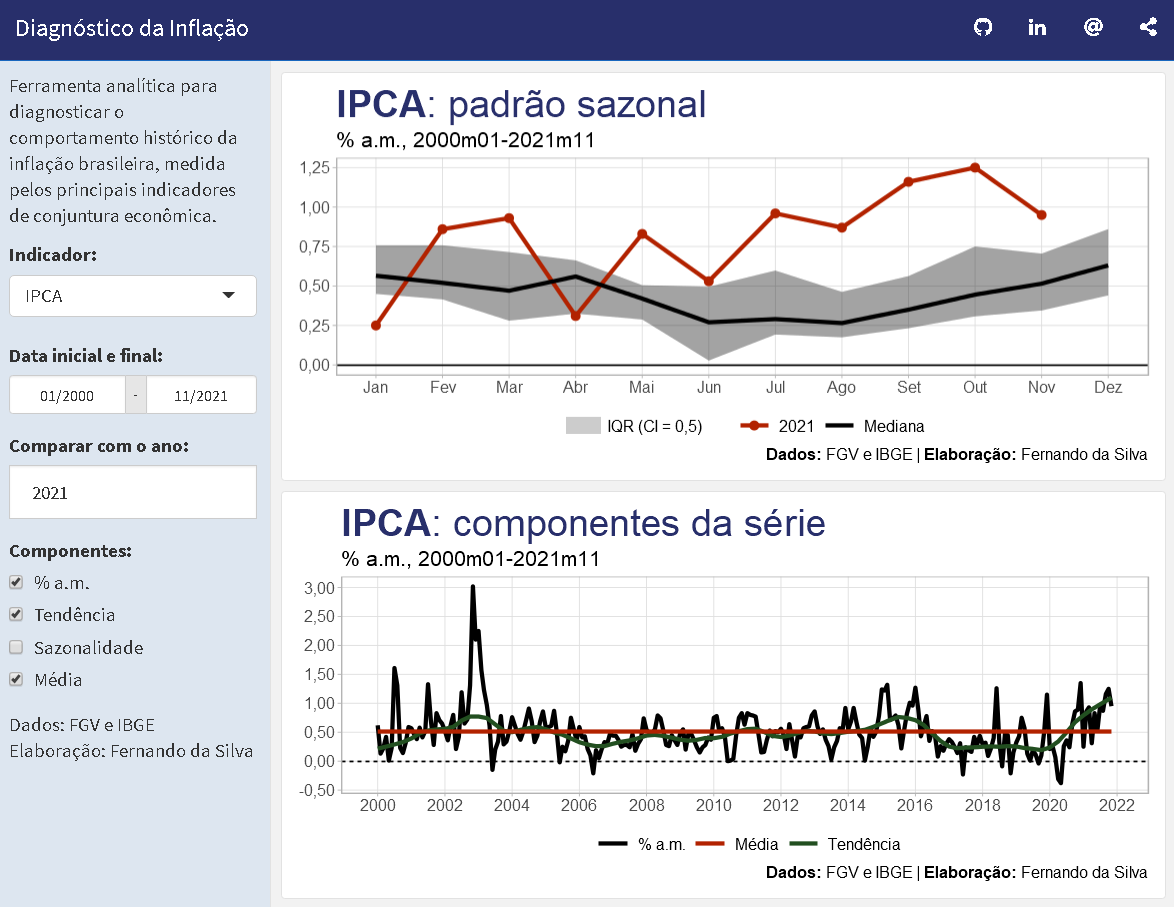
Códigos de replicação completos estão disponíveis para membros do Clube AM, aqui exibiremos apenas uma demonstração. Para aprofundamento e detalhes sobre análise de conjuntura, códigos e muitos mais, confira os cursos aplicados da Análise Macro.
Guia prático de desenvolvimento
Para criar uma dashboard dinâmica no R podemos seguir alguns passos gerais, resumidos a seguir com base no exemplo exposto:
- Criar um projeto de RStudio (organização é importante!);
- Criar um template/estrutura/layout para a dashboard ({flexdashboard} + {shiny});
- Definir lógica de consumo de dados (banco de dados, extração via pacotes, automatização?);
- Definir elementos de interação (botões, campos, filtros, etc.);
- Definir elementos visuais (tabelas, gráficos, etc.).
Alguns desses passos não são necessariamente sequenciais, sendo também importante adotar a prática de tentativa & erro para confirmar o funcionamento a cada pequena alteração/incremento que você realizar na dashboard. Por experiência prática, não deixe para renderizar sua dashboard somente no final, caso contrário observará um erro que pode ser uma máscara para uma série de outros erros que você não percebeu pois não visualizou a dashboard renderizada por cada "pequena parte". Nesse caso, te desejo boa sorte até chegar na origem do erro! Com tentativa & erro constante você aprende mais rápido e corrige o que está errado no momento certo.
Outros procedimentos interessantes, após a finalização do desenvolvimento da dashboard, é definir como e onde você publicará o resultado de todo esse trabalho. Em nosso caso, o serviço Shinyapps é muito conveniente e (com limitações) gratuito, gerando um link de compartilhamento conforme referenciado acima. Por fim, vale mencionar que o uso de versionamento de código ajuda na organização (Git/GitHub).
Pacotes e framework
Agora vamos abrir o RStudio e colocar esse guia em prática! Para construir a dashboard você precisará dos seguintes pacotes disponíveis em sua instalação de R:
Optou-se por utilizar o framework dos pacotes {flexdashboard} + {shiny}, que oferecem uma sistemática de programação reativa e sintaxe simples e amigável, respectivamente, tornando o processo de criação de dashboards dinâmicas mais fácil. Além disso, a dashboard foi hospedada no serviço shinyapps.io e automatizada usando o GitHub Actions (confira neste link um tutorial a respeito).
Criando o projeto e template da dashboard
O primeiro passo é criar um projeto do RStudio, para isso você pode usar o comando usethis::create_project("nome_do_projeto") ou navegar pelos menus no RStudio.
Em seguida, criamos o arquivo principal da dashboard utilizando o template básico oferecido pelo pacote {flexdashboard}: basta navegar pelos menus File > New File > R Markdown > From Template > Flex Dashboard {flexdashboard} > OK e salvar o arquivo .Rmd na raiz do projeto.
No arquivo editamos os metadados com as definições desejadas para a dashboard, conforme abaixo:
Importação de dados
Agora podemos começar a trabalhar nos dados e elementos visuais da dashboard. No primeiro chunk de R do documento (global) especificamos os pacotes, carregamos os dados e definimos objetos úteis a serem utilizados nos gráficos. O chunk possui uma única opção de chunk que é include=FALSE.
Os dados ficam salvos em uma pasta chamada "data" (criada previamente) e são atualizados automaticamente por um script independente, visando diminuir dependências e tempo de carregamento da dashboard. Neste link você pode baixar os dados para poder reproduzir o exemplo.
Botões de interação
Em seguida, criamos uma coluna usando cabeçalho Markdown de nível dois (------------------) e determinamos que esse elemento seja a sidebar da dashboard (atributo {.sidebar}). Essa barra lateral é, usualmente, onde são exibidos os filtros e opções de interatividade, além de poder servir de espaço para textos informativos. No nosso exemplo, colocamos um texto breve e definimos, conforme chunk abaixo, um input do tipo "botão de seleção/dropdown" através do {shiny} para aplicar filtros e manipulações de dados (selecionar indicador para exibição):
Elementos visuais: gráficos
Uma vez definidos os inputs, passamos à construção dos outputs que será um único gráfico neste caso. Para tal, criamos mais uma linha, que será responsável pela exibição dinâmica e interativa do indicador selecionado pelo usuário no botão criado acima. Para essa dinâmica funcionar utilizamos a expressão input$nome_do_input no script, conectando o botão ao output (gráfico) dentro de uma função renderizadora (renderPlot() ). Ou seja, pegamos o valor selecionado pelo usuário no botão, filtramos os dados já carregados e jogamos o resultado para um gráfico de linha. O gráfico pode ser criado por diversos pacotes disponíveis no R, aqui escolhemos o famoso {ggplot2}. O código abaixo demonstra isso:
Renderização
Os códigos são extensos (aqui cortamos várias linhas, na verdade, por simplificação), mas não se assuste se você não entendeu alguma coisa. Com a prática e a ajuda de algum curso esse processo de aprendizagem fica bem mais fácil.
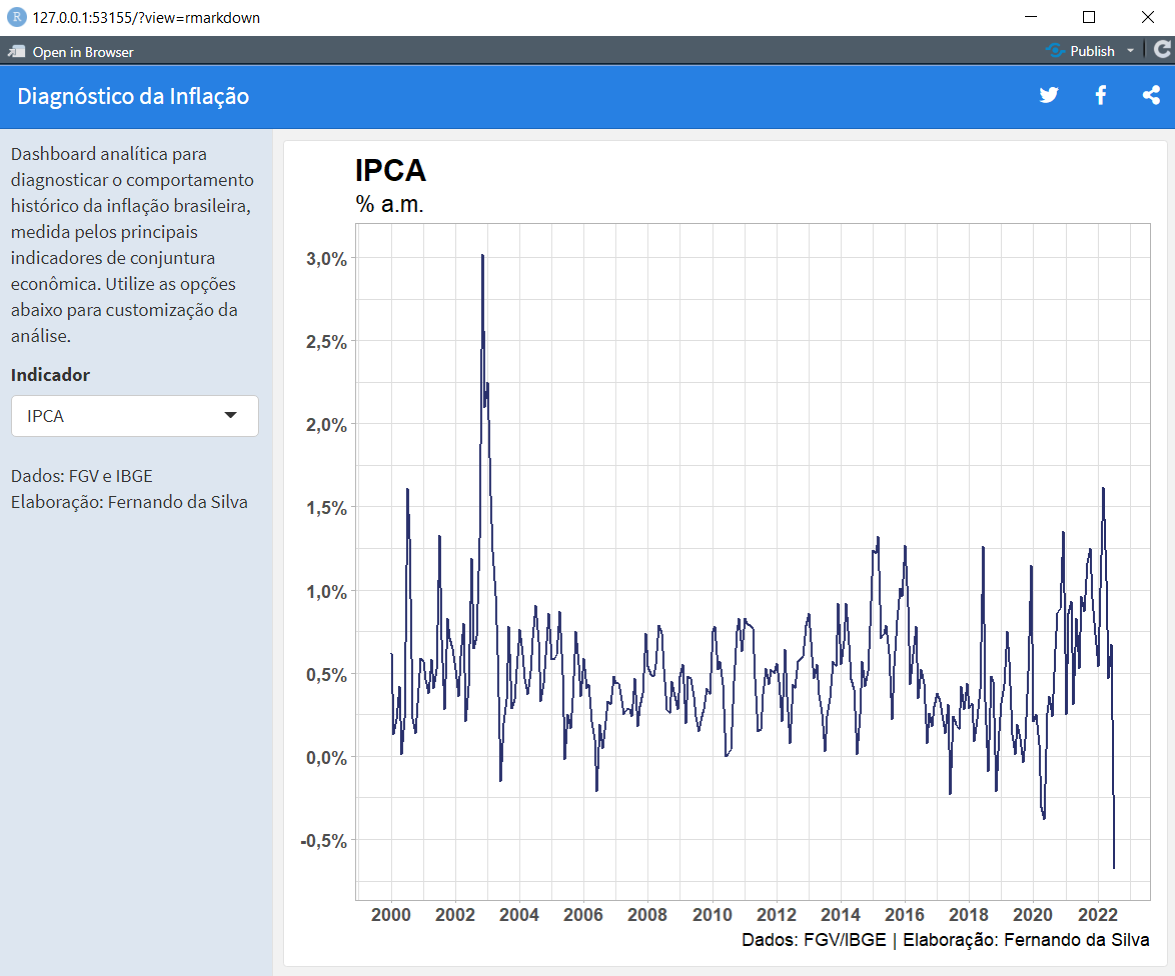
Após gerar os elementos visuais, utilize o botão Run Document no RStudio para visualizar o resultado, ou seja, a dashboard propriamente dita (conforme a imagem a seguir). Os últimos passos envolvem fazer o deploy da dashboard e automatizar a coleta inicial de dados. Consulte as referências inicias para orientação sobre o assunto e os cursos da Análise Macro para uma ajuda.
Saiba mais
Você pode se aprofundar nos assuntos aqui expostos brevemente e entender os detalhes através destes cursos da Análise Macro:

