Todos sabemos que boa parte do trabalho na análise de dados está contido na limpeza de dados. Para quem está no começo da aventura nesse mundo pode se assustar, afinal, dados "sujos" são mais comuns do que pode parecer. No Hackeando o R de hoje, iremos mostrar como pacote {janitor} pode ajudar iniciantes na limpeza de dados.
library(tidyverse) library(janitor) library(knitr) library(sidrar) library(lubridate)
Primeiro, iremos coletar um dataset para que possamos exemplificar algumas funções. A tabela 1620 do SIDRA que se refere as Contas Nacionais Trimestrais, com enfoque no setor agropecuário.
agro <- sidrar::get_sidra(api = "/t/1620/n1/all/v/all/p/all/c11255/90687,90707/d/v583%202") kable(head(agro[,4:10]), align = "c")
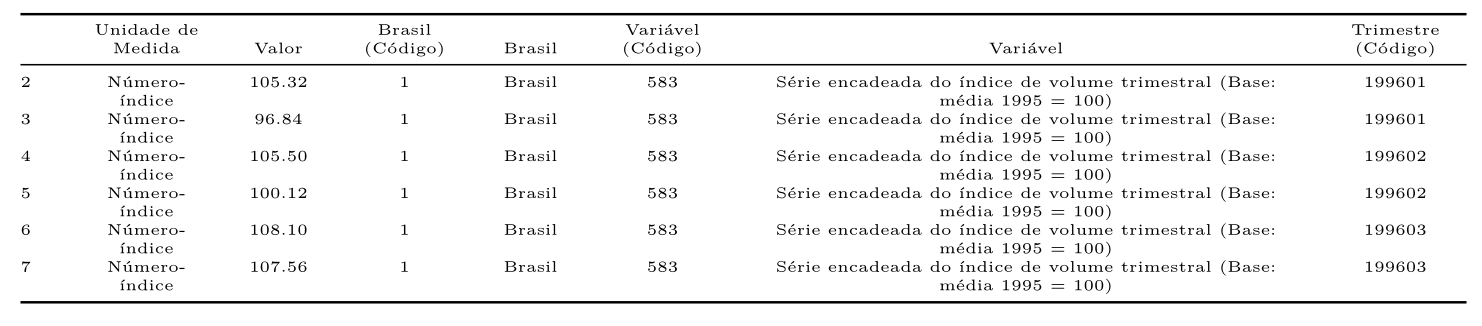
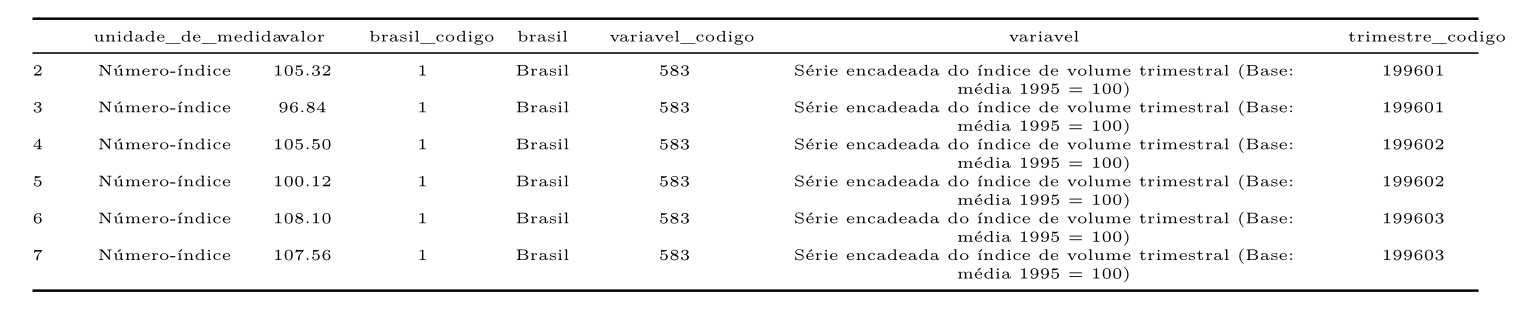
Um das maiores dificuldades que encontramos no R são as formas que os nomes das colunas se idendificam. Muitas vezes o R simpleste não reconhece o formato, ou se torna complicado utilizar certos caracteres nas funções. A função clean_names() facilita a limpeza dos nomes das colunas, retirando caracteres e formatando na forma que o R melhor funciona. Veja a diferença
agro1 <- agro %>% clean_names() kable(head(agro1[,4:10]), align = "c")
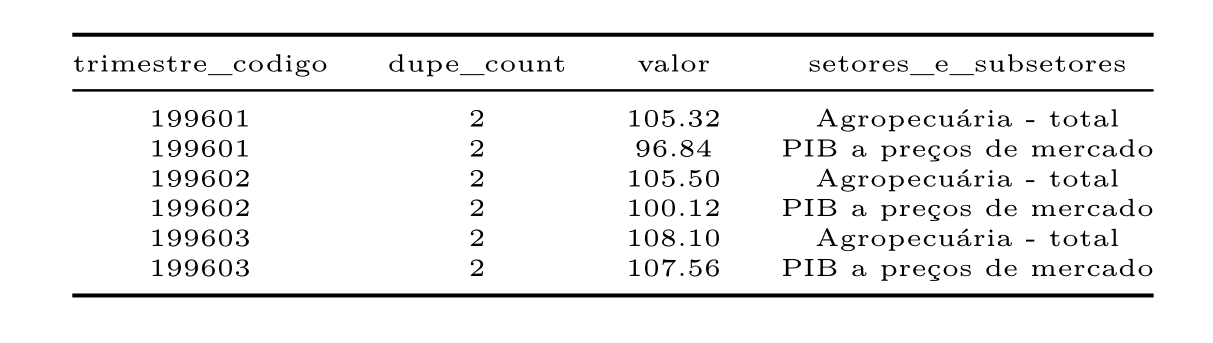
Também podemos encontrar data frames que possuem observações duplicadas. Podemos utilizar a função get_dupes() para confirmar se ocorre isto com nossos dados. Veja que é criado uma coluna informando o fato.
agro1 %>% select(trimestre_codigo, valor, `setores_e_subsetores`) %>% get_dupes(trimestre_codigo) %>% head() %>% kable(align = "c")
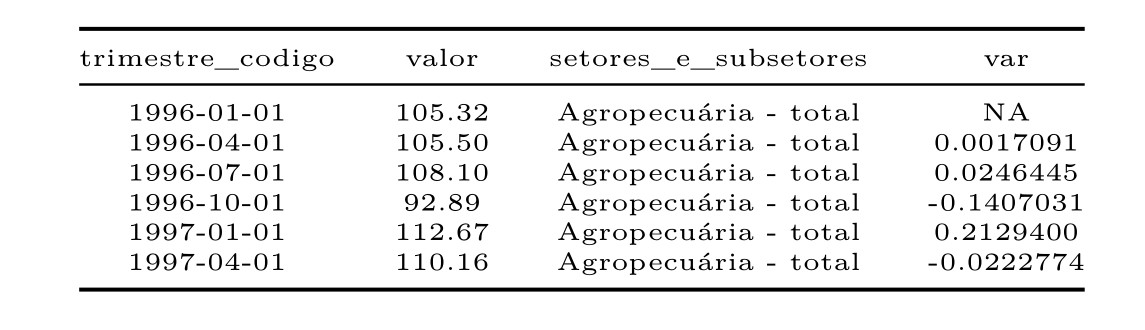
Feito as transformações das colunas e a confirmação de há duas observações iguais, pelo fato de existir mais de uma variável, podemos seguir com a limpeza padrão, transformando a data e realizando cálculos.
agro_total <- agro1 %>%
select(trimestre_codigo, valor, `setores_e_subsetores`) %>%
filter(`setores_e_subsetores` == "Agropecuária - total") %>%
mutate(trimestre_codigo = quarter(yq(trimestre_codigo), type = "date_first"),
var = (valor/lag(valor,1)-1))
kable(head(agro_total), align = "c")
Para melhorar a análise, podemos utilizar a função round_half_up() para que possamos arredondar facilmente nossos dados. Além de utilizar a função adorn_pct_formatting() que personaliza nosso data frame, multiplicando um valor decimal por 100 e insere o caractere "%".
agro_total1 <- agro_total %>% mutate(valor_round_up = round_half_up(agro_total$valor)) %>% adorn_pct_formatting(,,,var) kable(head(agro_total1), align = "c")
O pacote também oferece outras funções interessantes como tabyl(), que permite contruir uma tabulação com a contagem e porcentagem de variáveis, podendo ser muito utilizada em análise de grupos. A função excel_numeric_to_date(), que realiza a transformação de uma data serial importada do excel na classe Date.
________________________
(*) Quer aprender mais sobre a linguagem R? confira nosso Curso de Introdução ao R para análise de dados.
________________________


