A natureza e a prática da previsão
Uma previsão é apenas uma possibilidade, dentre tantas possíveis, que pode ou não ocorrer no futuro. Ao contrário, entretanto, do que muitas pessoas pensam, existem técnicas estatísticas relativamente simples para tornar essa previsão a mais acurada possível.
A relevância do que faremos ao longo das próximas semanas é evidente. Gerar previsões, afinal, é um problema importante para áreas tão distintas quanto negócios em geral, processo industrial, políticas públicas, macroeconomia, ciências físicas, medicina, política, ciências sociais, finanças, etc. A necessidade de identificar cenários possíveis para variáveis estratégicas é algo que perpassa uma infinidade de áreas, possibilitando aos que conhecem os métodos quantitativos e qualitativos para isso uma grande vantagem competitiva. Sendo um pouco mais detalhista, podemos dizer que forecasting possui amplo impacto, tal qual:
- Gerenciamento de operações: Previsões de oferta e demanda por bens e serviços são cruciais para determinar o quanto de estoque deve-se manter em um determinado período de tempo. Muito estoque é ruim, porque envolve custo de oportunidade. Pouco estoque pode frustar vendas. Saber o ponto de equilíbrio depende de projeções acuradas sobre produção e vendas;
- Marketing: Previsões são extremamente relevantes para decisões de marketing. Previsões de resposta em termos de venda de um anúncio, novas promoções, mudanças em políticas de preços, dentre outras, permitem aos tomadores de decisão avaliar sua efetividade, possibilitando que metas sejam atingidas;
- Finanças e gerenciamento de risco: Investidores estão a todo o tempo interessados em avaliar o retorno sobre potenciais ativos. Tais ativos incluem uma gama bastante diversificada, como ações, fundos, commodities, dentre outros. Gerenciar o risco de um investimento implica, desse modo, em conseguir prever de forma adequada a volatilidade do retorno de um ativo, assim o risco associado a uma carteira de investimento pode ser avaliado, assegurando que o retorno sobre aquele conjunto de ativos possa ser corretamente calculado;
- Economia: Governos, instituições financeiras, consultorias, dentre outros, requerem projeções sobre uma infinidade de variáveis econômicas, tais como inflação, crescimento do PIB, desemprego, taxas de juros, produção, consumo, etc. Tais projeções estão por trás da condução da política econômica por parte de governos, bem como fazem parte da tomada de decisões de grandes empresas. Obs. Qualquer plano estratégico deve conter uma avaliação do cenário macroeconômico.
- Controle de processos industriais: A qualidade de um processo industrial se torna otimizada quando características importantes podem ser previstas a contexto;
- Demografia: Previsões acuradas sobre a população de um país são feitas de forma rotineira. Seja de forma agregada ou por grupos específicos, tendo como objetivo a provisão de serviços públicos por parte dos governos - como fundos de aposentadoria ou serviços de saúde e educação - seja por empresas interessadas em determinados extratos da população.
Esses são apenas alguns exemplos do quanto gerar previsões acuradas constitui alicerce fundamental para a tomada de decisões. Em termos práticos, um ponto importante a considerar diz respeito ao horizonte de previsão. Costuma-se delimitar previsões em termos de curto prazo, médio prazo e longo prazo.
Previsões de curto prazo se dão em termos de dias, semanas ou no máximo meses. Já previsões de médio prazo se fazem entre um e dois anos, enquanto previsões de longo prazo estendem-se por vários anos. Previsões de curto e médio prazo são tipicamente baseadas na identificação, modelagem e extrapolação de padrões observados nos dados passados. Isso porque, dados passados em geral apresentam um comportamento inercial, não se modificando de forma dramática ao longo do tempo. Essa importante característica abre espaço para o uso de métodos estatísticos.
Aqui, claro, estamos supondo que existem dados disponíveis. Nem sempre, entretanto, é o caso. Por exemplo, imagine que você seja empreendedor e queira abrir uma empresa inovadora. Seu produto não é conhecido, logo não há histórico sobre a sua demanda, nem muito menos sobre sua oferta. Seria possível gerar uma previsão de vendas para o primeiro ano de operação? Isto é, você seria capaz de construir um fluxo de caixa a partir de um produto que não existe no mercado? Complicado, não é mesmo?
Como exposto em Hyndman e Athanasopoulos (2013), um ponto inicial a considerar sobre previsões é justamente o que pode ser previsto. Dificilmente, por exemplo, você conseguiu prever os números que saíram na mega-sena da virada. Por outro lado, é relativamente fácil prever a hora que o sol se porá amanhã. De maneira geral, o grau de previsibilidade de um determinado evento ou observação futura vai depender de três condições:
- O quanto nós sabemos sobre os fatores que influenciam determinado evento ou variável;
- Existem dados disponíveis?
- O quanto as previsões que estamos fazendo podem afetar os eventos ou observações futuras?
A demanda futura de eletricidade é algo previsível dado que as três condições acima são satisfeitas.
A previsão da taxa de câmbio, por outro lado, não é algo muito simples. Isto porque, existe um conjunto muito grande de variáveis que pode influenciar o câmbio, bem como as taxas futuras serão influenciadas pelas expectativas que se formam sobre elas. Quem nunca ouviu falar que o mercado antecipa o futuro? Esse comportamento dos agentes econômicos dificulta soberbamente o trabalho de previsão.
Tais condições são importantes para delimitar a natureza do trabalho de previsão. Há eventos que, sim, podem ser previstos com elevada acurácia, bem como há eventos que não podem ser previstos de maneira alguma.
Ademais, é preciso compreender também que a despeito de técnicas estatísticas, o trabalho de previsão não é apenas isso. Uma grande parte dele envolve arte. O analista deve se manter muito bem informado sobre os fatores que influenciam a variável de interesse, de sorte que consiga construir um intervalo de previsão satisfatório para ela, considerando os dados disponíveis. Em outras palavras, muitas vezes o analista terá de traduzir uma análise qualitativa em números, de modo a construir uma previsão satisfatória para a variável de interesse.
Previsões qualitativas vs. Previsões quantitativas
Quando aquelas três condições não são satisfeitas, integral ou parcialmente, será necessário recorrer a previsões qualitativas. O lançamento de um novo produto no mercado dificilmente poderá conter com uma análise estatística, dado que não existem dados disponíveis. Entretanto, será possível delimitar o público-alvo que aquele produto quer atingir, bem como comparar o potencial do produto com outros similares previamente existentes.
O foco principal de nossa jornada será, entretanto, a análise quantitativa, quando poderemos dar total atenção aos dados disponíveis e aos modelos de previsão. Nosso objetivo aqui será coletar e tratar os dados, identificar modelos possíveis, diagnosticar sua adequação aos dados, gerar previsões a partir desses modelos dado um conjunto de cenários possíveis, bem como avaliar as previsões geradas.
O processo de previsão
Um processo é uma série de atividades conectadas que transforma um ou mais inputs em um ou mais outputs. Para o nosso trabalho de previsão, teremos que considerar as seguintes atividades:
- Definição do problema
- Coleta dos Dados
- Análise dos Dados
- Identificação do modelo e estimação
- Diagnóstico dos modelos estimados
- Implantação do modelo de previsão
- Avaliação do modelo de previsão
A definição do problema envolve compreender como as previsões serão utilizadas pelo usuário, o que requer saber de quanto em quanto tempo elas precisam ser atualizadas, qual é o horizonte de previsão, qual o grau de acurácia necessário, os riscos associados às previsões geradas, etc. A definição do problema de previsão precisa ser feito levando em consideração as expectativas daqueles que as utilizarão.
A coleta de dados consiste em obter dados históricos não apenas sobre a variável de interesse, mas também daquelas a ela associadas, isto é, suas potenciais variáveis explicativas. A análise de dados, por sua vez, é um processo de suma importância para tornar os dados prontos para serem modelados. Isso envolve reconhecer padrões sazonais, tendências, outliers, estatísticas descritivas, existência de inércia, etc.
Uma vez cumpridas as três etapas acima, é possível passar para a parte de modelagem e previsão propriamente dita. A começar pela identificação do modelo mais adequado. Para prever uma série com inércia elevada, por exemplo, pode fazer mais sentido em termos de custo-benefício optar por uma modelagem univariada.
Construir modelos multivariados pode ter um custo muito alto, com retorno, em termos de acurácia de previsão, pouco satisfatório, quando comparado a modelos univariados. Para isso, claro, será preciso conhecer uma pilha de modelos, identificando aquela que seja mais adequado para a variável de interesse. Uma vez feita a escolha, é feita a estimação, com base em método que pode ser mínimos quadrados ou bayesiano, por exemplo.
Escolhido e estimado o modelo, é preciso avaliar o quão bem eles se aderem aos dados observados.
Resíduos mal comportados estão associados a previsões pouco acuradas. Desse modo, essa etapa é de suma importância para a construção de intervalos de previsão satisfatórios.
Caso o modelo consiga passar por essa etapa, deve-se passar à etapa de previsão: gerando as previsões e avaliando o quão boas elas são. Para tal, será necessário reservar uma parte dos dados para que essa avaliação seja possível.
Exemplos no R
Para obter todo o código em R e Python para os exemplos abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais.
No R, existem diversos frameworks para auxiliar na construção de análise e previsão de séries temporais, e portanto, na previsão de variáveis macroeconômicos. A família de pacote tidyverts poderá nos auxiliar ao máximo pois permite a construção de diversos tipos de análise gráfica, decomposição, modelagem e verificação de resíduos.
Os objetos devem possuir a classe tsibble, em qual possui uma coluna de índice de tempo, das variáveis e possíveis grupos de variáveis.
Vamos ver alguns exemplos de variáveis que poderíamos estar interessados em gerar previsões? Para isso, você deve carregar o pacote fpp3. Uma vez instalado e carregado, você poderá alguns datasets lá disponíveis.
Para ver todos os datasets disponíveis, use o comando data(package='fpp2').
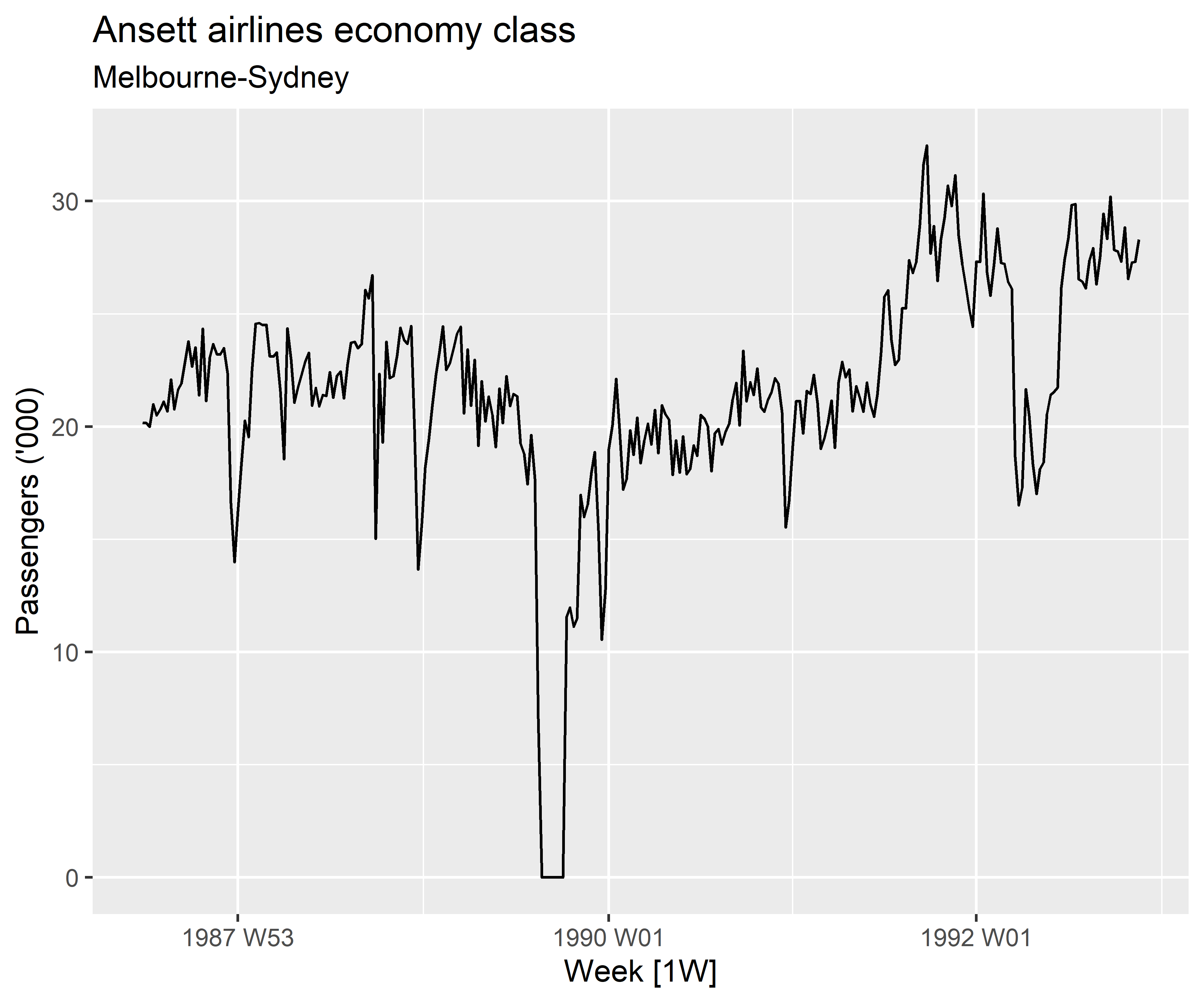
Para séries temporais, o gráfico mais óbvio de se iniciar é o gráfico de linha para séries temporais, em que as observações (eixo y) são plotadas de acordo com o tempo da observação (eixo x), a partir de uma linha contínua. O gráfico abaixo demonstra a carga semanal de passageiros econômicos na Ansett Airlines entre as duas maiores cidades da Austrália.
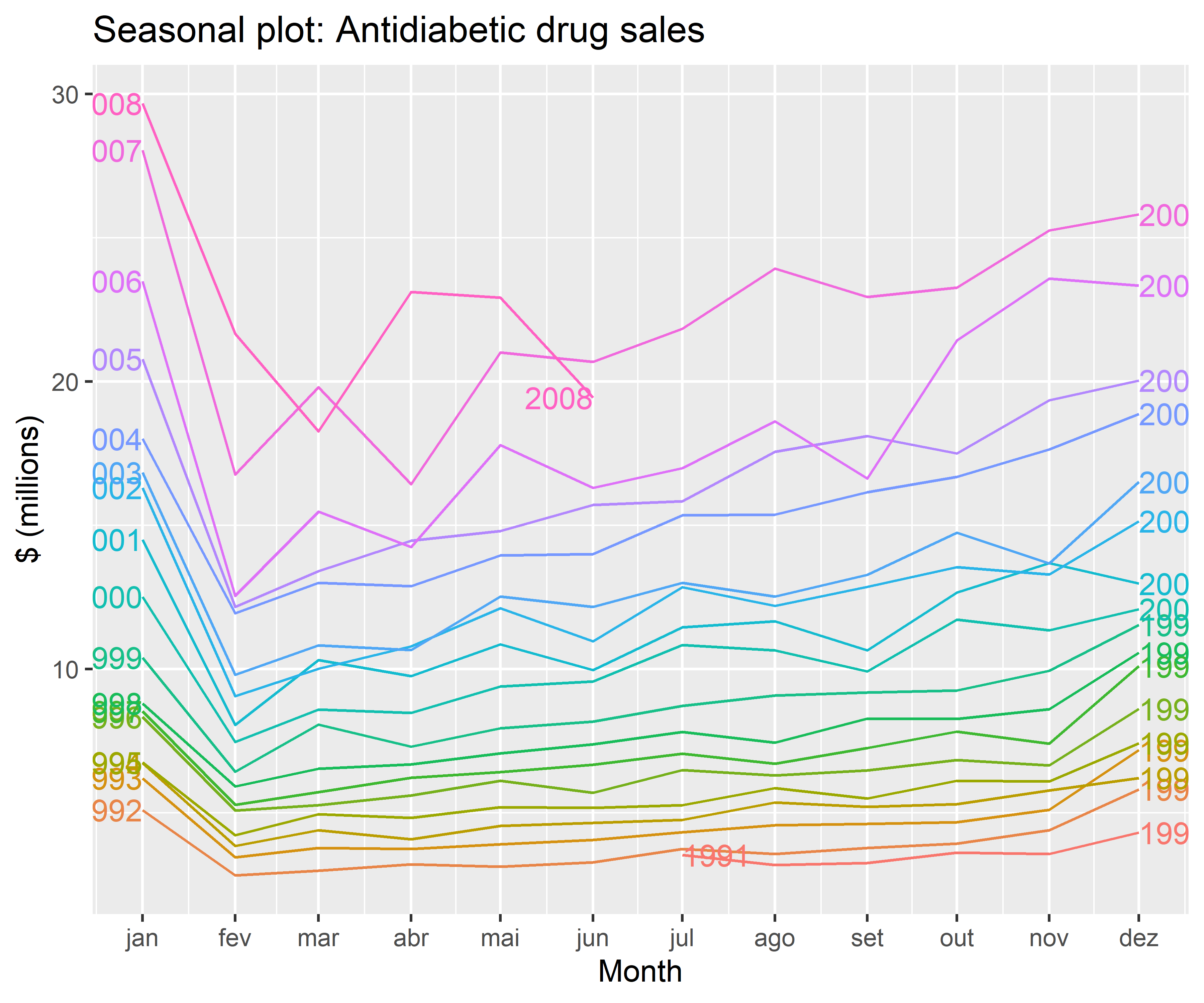
Outros tipos de gráficos interessantes para analisar séries temporais referem-se aos gráficos de sazonalidade.
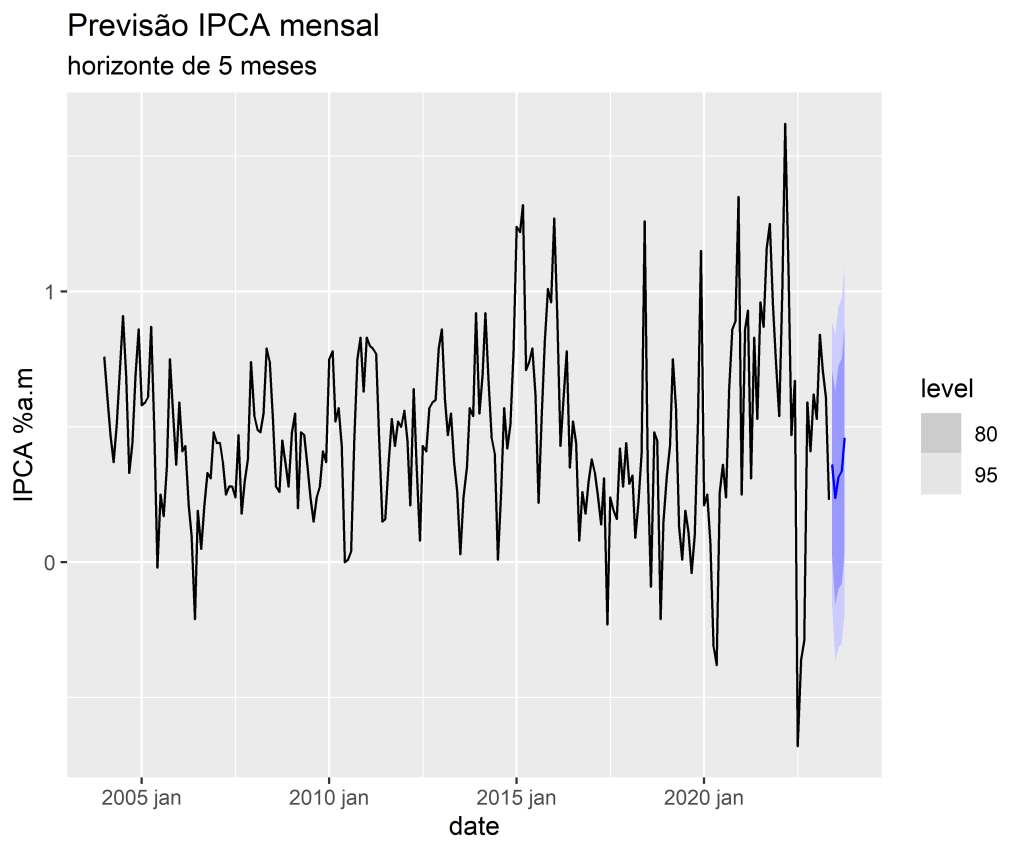
E por fim, é possível construir rapidamente um gráfico de previsão.
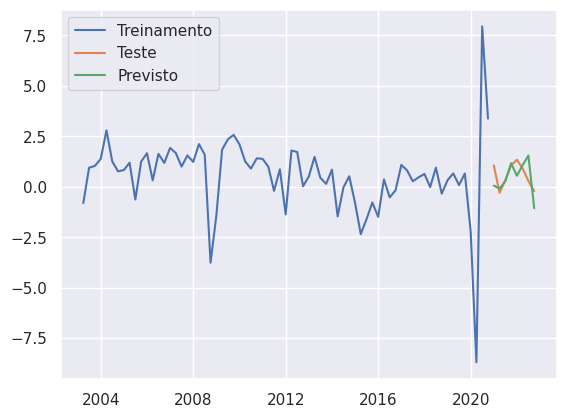
 Exemplo no Python
Exemplo no Python
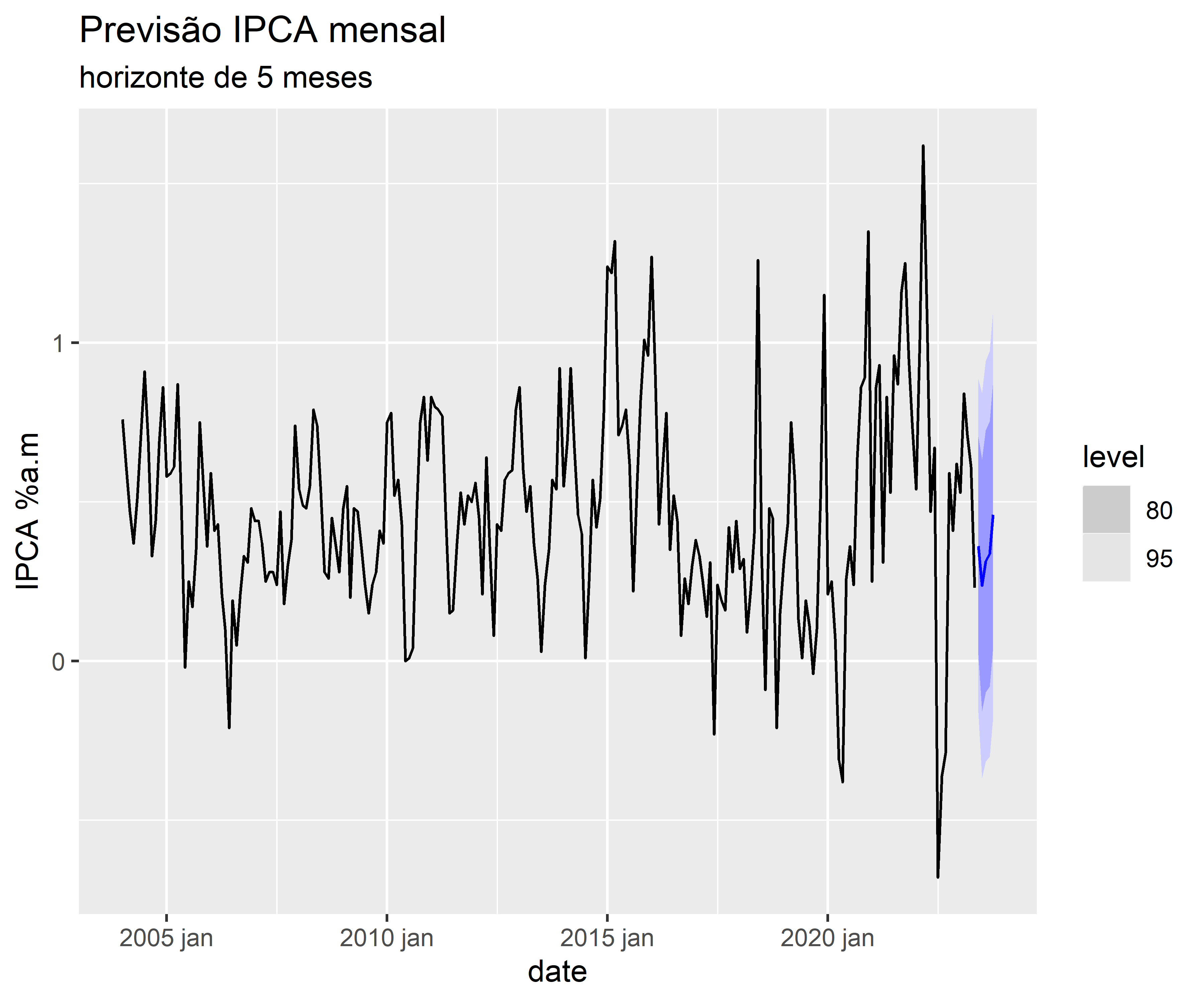
No Python, podemos ter a ajuda da biblioteca statsmodels e matplotlib/seaborn para criar os gráficos referentes a séries temporais. Por exemplo, é possível criar um modelo de previsão e comparar os dados previstos com os ocorridos.
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.

