Os microdados da Pesquisa Nacional por Amostra de Domicílios Contínua (PNADC), produzida pelo IBGE, possuem uma riqueza enorme de informação de um conjunto de indicadores relacionados à força de trabalho no país, constituindo um verdadeiro tesouro para economistas e cientistas sociais. Esse grande volume de dados exige, por consequência, o uso de ferramentas adequadas para o tratamento, análise, visualização e sua utilização em geral. Em suma, é necessário utilizar linguagens de programação para "colocar a mão" nesses dados e, neste exercício, mostraremos como fazer isso usando o R.
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
1) Importar microdados trimestrais
Para começar o exercício, vamos importar os microdados para o environment do R usando o pacote PNADcIBGE - que foi desenvolvido pela própria equipe do IBGE. Os microdados trimestrais serão o alvo do nosso exemplo: apontamos na função get_pnadc o último período (ano/trimestre) disponível da pesquisa e, opcionalmente, as variáveis de interesse1.
2) Análise de dados
Após este simples comando de importação executado, os microdados da PNADC já estão disponíveis para fazermos uma análise. A função, inclusive, já configura o plano amostral internamente através do argumento design = TRUE - mas o usuário pode desabilitar para obter os dados brutos -, sendo assim podemos usar o pacote survey para obter, por exemplo, o total de homens e mulheres:
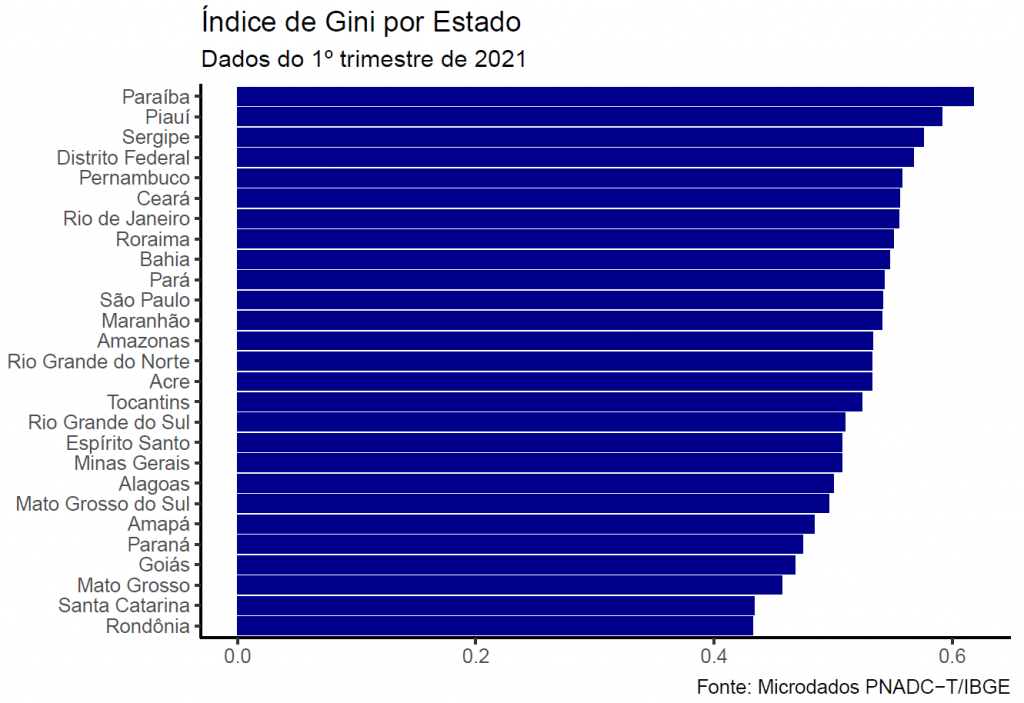
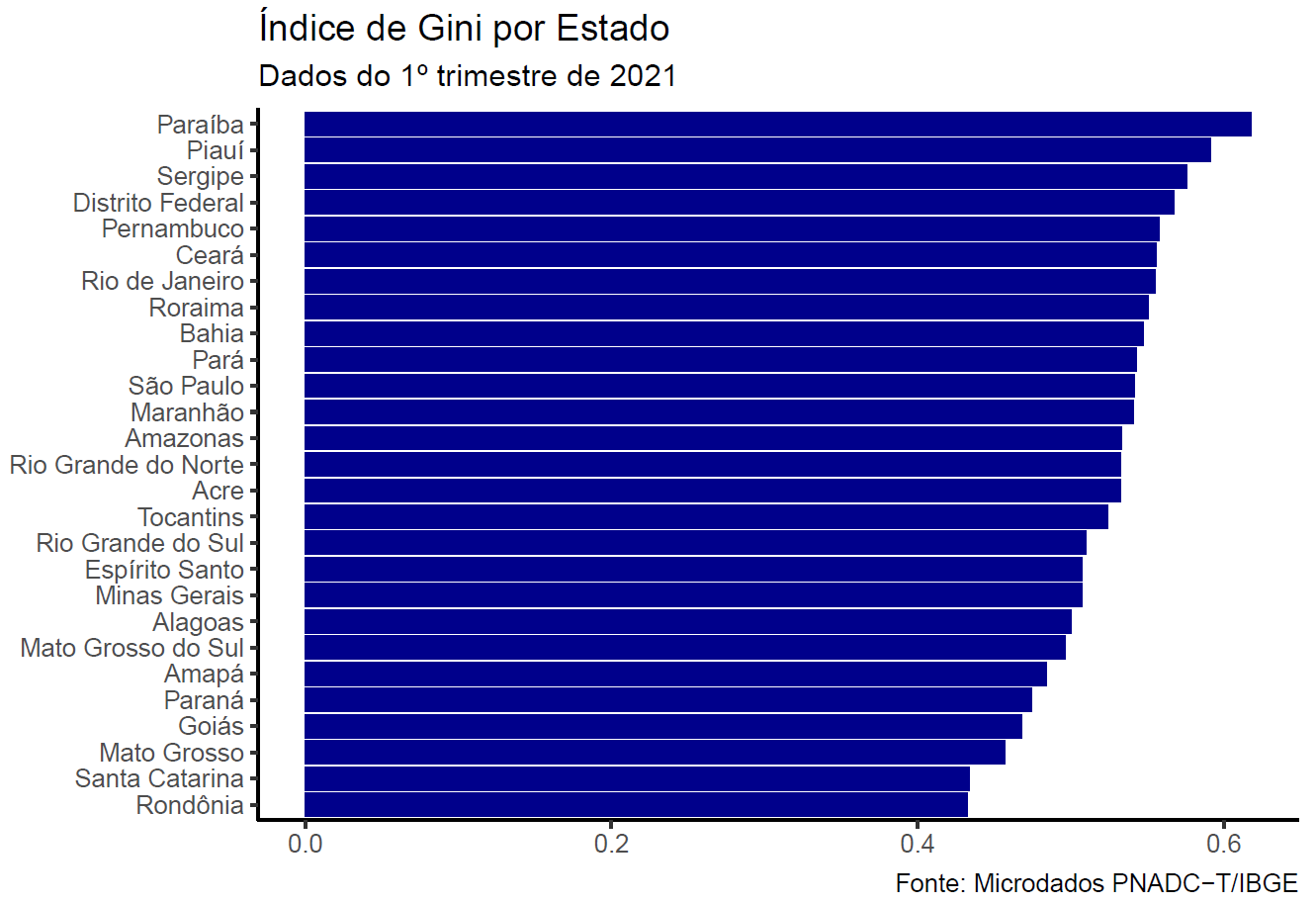
Da mesma forma, e com comandos simples, o usuário pode estimar o índice de Gini a nível nacional:
Diversas outras análise podem ser feitas, como esta publicada no blog da Análise Macro:
Saiba mais
Para saber mais e se aprofundar confira o blog da Análise Macro e os cursos aplicados de R e Python, especialmente:
[1] Note que os microdados consomem espaço excepcionalmente grande na memória do computador, portanto, evite a importação sem nenhum tipo de filtro de variáveis.

