Este exercício é um resumo de uma parte do curso de modelos preditivos da Análise Macro, onde o objetivo é desenvolver modelos macroeconômicos para tentar prever a taxa de câmbio (BRL/USD) através de um modelo monetário de preços flexíveis.
É bom pontuar logo de início que taxa de câmbio é uma variável macroeconômica extremamente imprevisível, sujeita a diversos ruídos e fatores que a caracterizam como um passeio aleatório. Portanto, sempre tome cuidado ao se deparar com previsões de taxas de câmbio, elas não devem ser levadas muito a sério (nem mesmo as previsões resultantes deste exercício). Por conta disso, nosso objetivo é apenas tentar construir um modelo que supere em termos de acurácia um modelo de passeio aleatório, o que já é bastante difícil. A previsão de um modelo de passeio aleatório é simplesmente a última observação realizada.
A seguir vamos obter uma visão geral de como este exercício pode ser realizado. Para todo o processo utilizamos a linguagem de programação R.
Sumário
1) Partimos de um modelo monetário de preços flexíveis com uma especificação parecida com essa abaixo, onde s é o log da taxa de câmbio nominal, m é o log da oferta de moeda, y é o log da produção industrial, i é o log(1 + x/100) da taxa de juros, a e b se referem aos países em análise — Brasil e USA, respectivamente — e τ pode ser uma constante ou outros fatores observáveis ou não.
![]()
2) Utilizamos os seguintes dados brutos para construção do modelo:
| Variável | País | Descrição | Fonte |
|---|---|---|---|
| Taxa de câmbio | Brasil/EUA | R$/US$ - Livre - Dólar americano (venda) - Fim de período - Freq. mensal | BCB |
| Oferta de moeda - M2 | Brasil | R$ mil - saldo em final de período - s.a. - Freq. mensal | BCB |
| Oferta de moeda - M2 | USA | US$ bilhão - s.a. - Freq. mensal | FRED |
| Produção industrial | Brasil/EUA | Índice (2015=100) - s.a. - Freq. mensal | OECD |
| Taxa de juros | Brasil | % a.a. - Selic acumulada no mês anualizada base 252 - Freq. mensal | BCB |
| Taxa de juros | USA | % a.a. - Federal Funds Effective Rate - Freq. mensal | FRED |
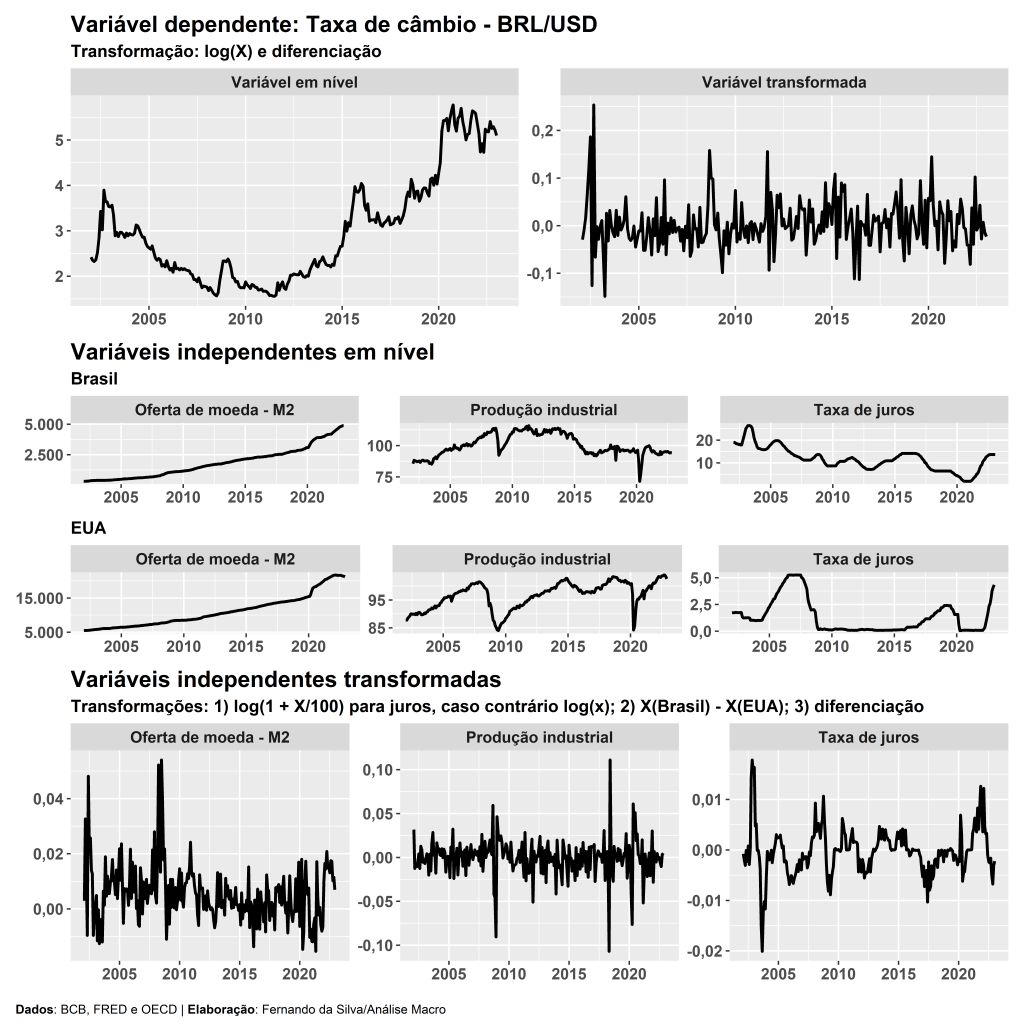
3) Os dados brutos foram coletados e tratados de maneira a obter as variáveis do modelo especificado e a característica de estacionariedade, apesar de haver perda de informação neste processo. A evolução das variáveis pode ser conferida no gráfico abaixo:
4) Como a finalidade do exercício é previsão, utilizamos o esquema de validação cruzada para fazer o backtesting de um conjunto de 3 estimadores: MQO, MQO com parâmetros variantes do tempo e XGBoost. Configuramos a validação cruzada de maneira a ter janelas amostrais com período inicial fixo para ajuste dos métodos, com acréscimo sucessivo de 1 observação até a totalidade de observações menos o período de previsão de interesse (12 meses). A cada iteração, os ajustes dos modelos são usados para obter previsão 12 meses à frente, o que pode ser caracterizado como uma previsão pseudo fora da amostra. Descrevemos os métodos em questão brevemente à seguir.
→ MQO: o método dos mínimos quadrados ordinários, no caso mais simples, permite relacionar linearmente uma variável de interesse y e uma única variável independente x. É um método que oferece uma maneira de encontrar uma estimativa para os coeficientes dessa relação ao minimizar a soma do quadrado dos resíduos. Ou seja, no caso múltiplo, com mais de uma variável independente, é a solução do seguinte problema de minimização:
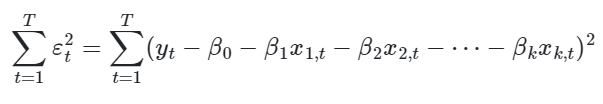
Saiba mais na Wikipédia.
→ MQO com parâmetros variantes no tempo (TVP): este método é uma extensão do MQO que permite que os coeficientes assumam valores diferentes conforme amostras de dados diferentes, ou seja, o valor dos βi não são fixos para todas as observações.
Saiba mais em Casas e Fernandez-Casal (2019).
→ XGBoost: é um algoritmo de aprendizagem de máquina que constrói um modelo de previsão com base em uma combinação de vários modelos de previsão considerados “fracos”, geralmente usando árvores de decisão (decision trees) e aumento de gradiente (gradient boosting). Isso significa que o algoritmo utiliza um método de otimização (método do gradiente) para minimizar uma função perda (como o RMSE) a cada modelo fraco adicional.
Saiba mais na Wikipédia e em Chen e Guestrin (2016).
5) Ao final do processo de validação cruzada obtemos uma medida de acurácia média entre todas as amostras de validação cruzada consideradas, após calcular o erro de previsão como o desvio do valor observado do valor previsto. Neste exercício consideramos o RMSE como métrica de acurácia e comparamos seu valor entre os métodos abordados acima e os modelos de passeio aleatório com e sem drift. O resultado pode ser observado no gráfico abaixo, que mostra o RMSE médio de validação cruzada de cada modelo por horizonte de previsão considerado.
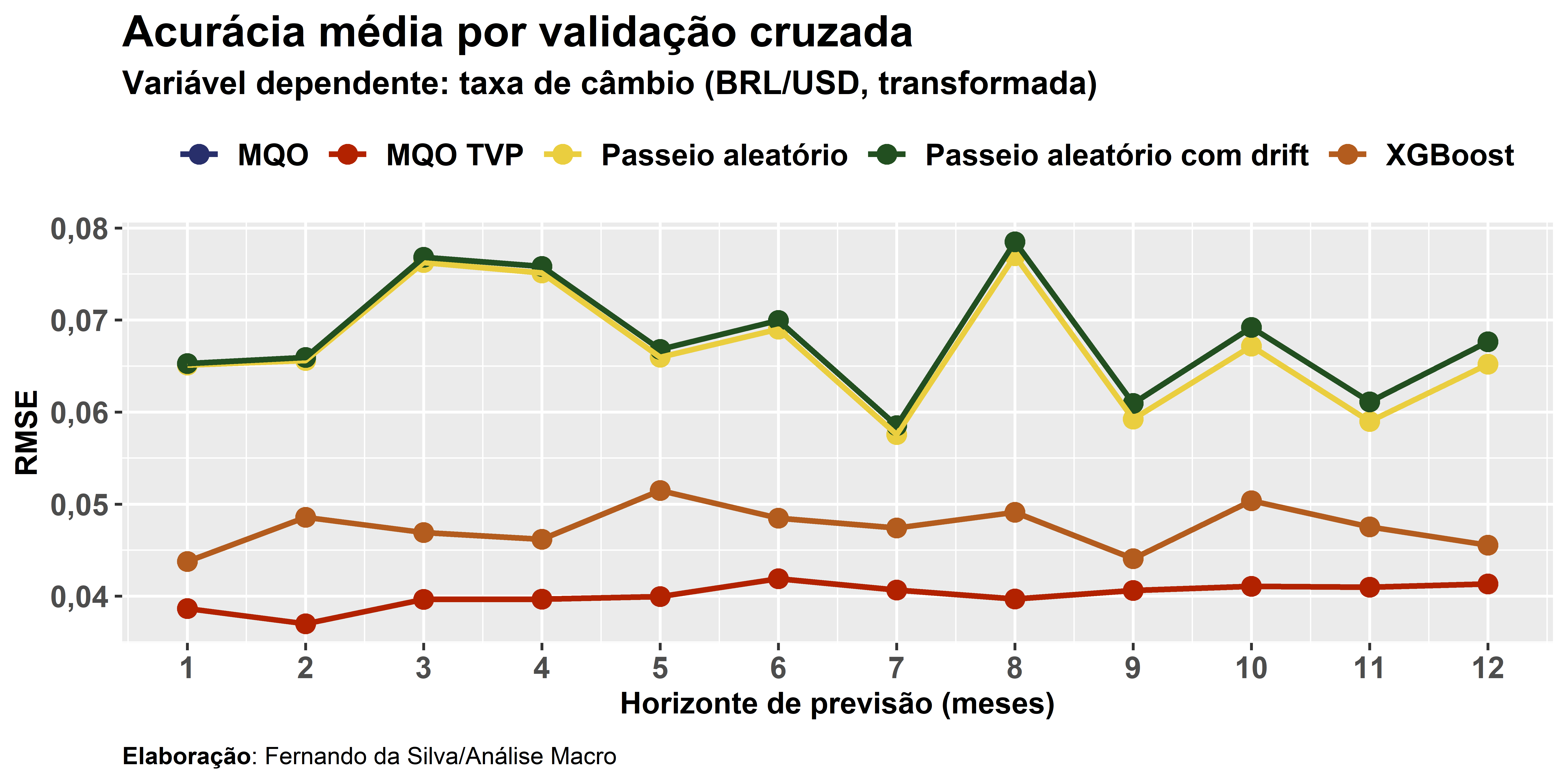
6) Analisando os resultados podemos concluir que, se o objetivo é estritamente previsão, é possível superar a acurácia de um modelo de passeio aleatório para previsão da taxa de câmbio e que modelos mais simples (MQO) são melhores que modelos mais complexos (XGBoost).
7) O último passo é criar cenários para as variáveis independentes do modelo para produzir previsões efetivamente fora da amostra para a variável dependente. Apesar de esta etapa não ser trivial e envolver julgamento, este procedimento é deixado como exercício para os interessados.
Por fim, pontuamos que este exercício simplificou em excesso diversos procedimentos importantes em um modelo de previsão para séries temporais, por questões de espaço e tempo. Uma investigação mais aprofundada sobre os dados, seus tratamentos, o modelo, os métodos de estimação e outros seria interessante e, com certeza, frutífera.
Vale também ressaltar que a taxa de câmbio é uma variável de interesse para o Banco Central do Brasil e, por isso, são coletadas expectativas (previsões) de profissionais de mercado sobre a mesma. Estes dados (suas estatísticas agregadas) são públicos e disponibilizados no sistema de expectativas (Focus), o que possibilita a comparação do erro de previsão destas previsões de mercado com os erros de previsão gerados por este exercício. De nada adianta ter um modelo mais acurado que um passeio aleatório, mas mais errático que as previsões de mercado, portanto essa comparação é importante. Pelo tratamento das variáveis neste exercício, porém, optamos por não fazer a comparação. Seria necessário retroceder as transformações aplicadas no exercício, o que não é impossível, além de aplicar alguns julgamentos ao lidar com os dados do Focus. Deixamos este procedimento, também, como exercício para os interessados.
Saiba mais
Códigos de reprodução em R deste exercício estão disponíveis para membros do Clube AM da Análise Macro.
Para se aprofundar no assunto confira os cursos aplicados de R e Python da Análise Macro:
- Trilha de Macroeconomia Aplicada: https://conteudosam.com.br/pacotes/macroeconomia-aplicada/
- Trilha de Machine Learning e Econometria: https://conteudosam.com.br/pacotes/econometria-e-machine-learning/
- Modelos Preditivos: https://analisemacro.com.br/curso/modelos-preditivos-de-machine-learning/
- Econometria: https://analisemacro.com.br/cursos/econometria/introducao-a-econometria/
- Análise de Séries Temporais: https://conteudosam.com.br/cursos/analise-de-series-temporais/
Referências
Casas, I., & Fernandez-Casal, R. (2019). tvReg: Time-varying coefficient linear regression for single and multi-equations in R. Available at SSRN 3363526.
Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In 22nd SIGKDD Conference on Knowledge Discovery and Data Mining.

