É conhecido que variáveis (comumente ditas como fatores), afetam o excesso de retorno de ações no geral. Um fator bastante difundido é o fator de risco de mercado utilizado no modelo Capital Asset Pricing Model. Nas últimas décadas, a literatura aprofundou-se nos estudos dos fatores que fazem parte da características das empresas, ampliando para o modelo de três fatores de Fama French, que introduziu os fatores Small Minus Big (SMB) e High minus Low (HML). Outros diversos fatores também são utilizados, a depender do mercado a ser investigado. O objetivo do post de hoje será utilizar fatores de investimento em conjunto com uma Regressão de Lasso para ajustar uma série de fatores de risco com o R.
Os fatores de risco são importantes mecanismo para traçar estratégias de investimento, principalmente para entender as características de ativos e antecipar possíveis movimentos de mercado. Como dito, é bem conhecido o fator Risco de Mercado, que leva em conta o risco sistemático produzido por um índice que representa o portfólio de mercado. O fator Small Minus Big (SMB), que representa a diferença do retorno de empresas com baixa capitalização e alta capitalização de mercado. High minus Low (HML), que representa a diferença do retorno de empresas com alto book-to-market e baixo book-to-market.
Outro fatores podem também ser levados em conta, tanto por conta da característica das empresas, quanto por fatores macroeconômicos. Adicionaremos mais três, sendo eles: Winners Minus Losers (WML), que leva em conta o retorno de ações que tiveram altos retornos no passado e ações que tiveram baixo retornos. Illiquid Minus Liquid (IML) que representa os retornos de ações com baixo liquidez e alta liquidez. E por fim, apenas um representado o fator macroeconômico de juros, que será a taxa de juros livre de risco, também útil para obter o excesso de retorno do ativo e do fator risco de mercado.
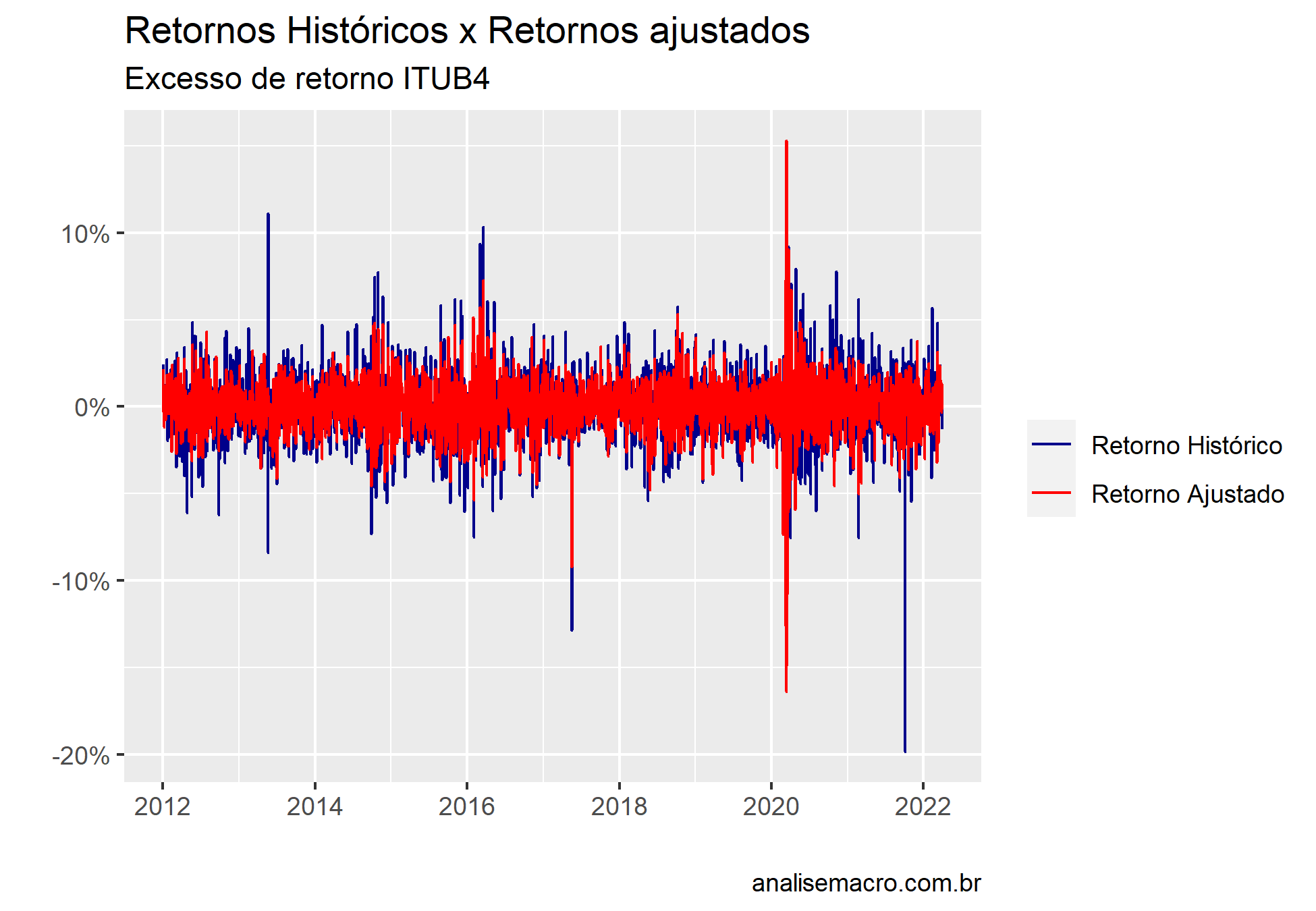
Todos os fatores são importados do site da NEFIN, onde também é detalhado a metodologia de criação de cada fator, bem como suas características. Para a ação que será utilizada como variável dependente, escolhemos a ITUB4 de forma totalmente aleatória, representado pelo seu log retorno diário dos preços ajustados.
O modelo utilizado será uma Regressão Lasso, útil para diminuir a limitação da regressão linear, representado pela seguinte equação:

Abaixo, representaremos os códigos para a importação dos dados do ativo selecionado e dos fatores disponibilizados pelo NEFIN.
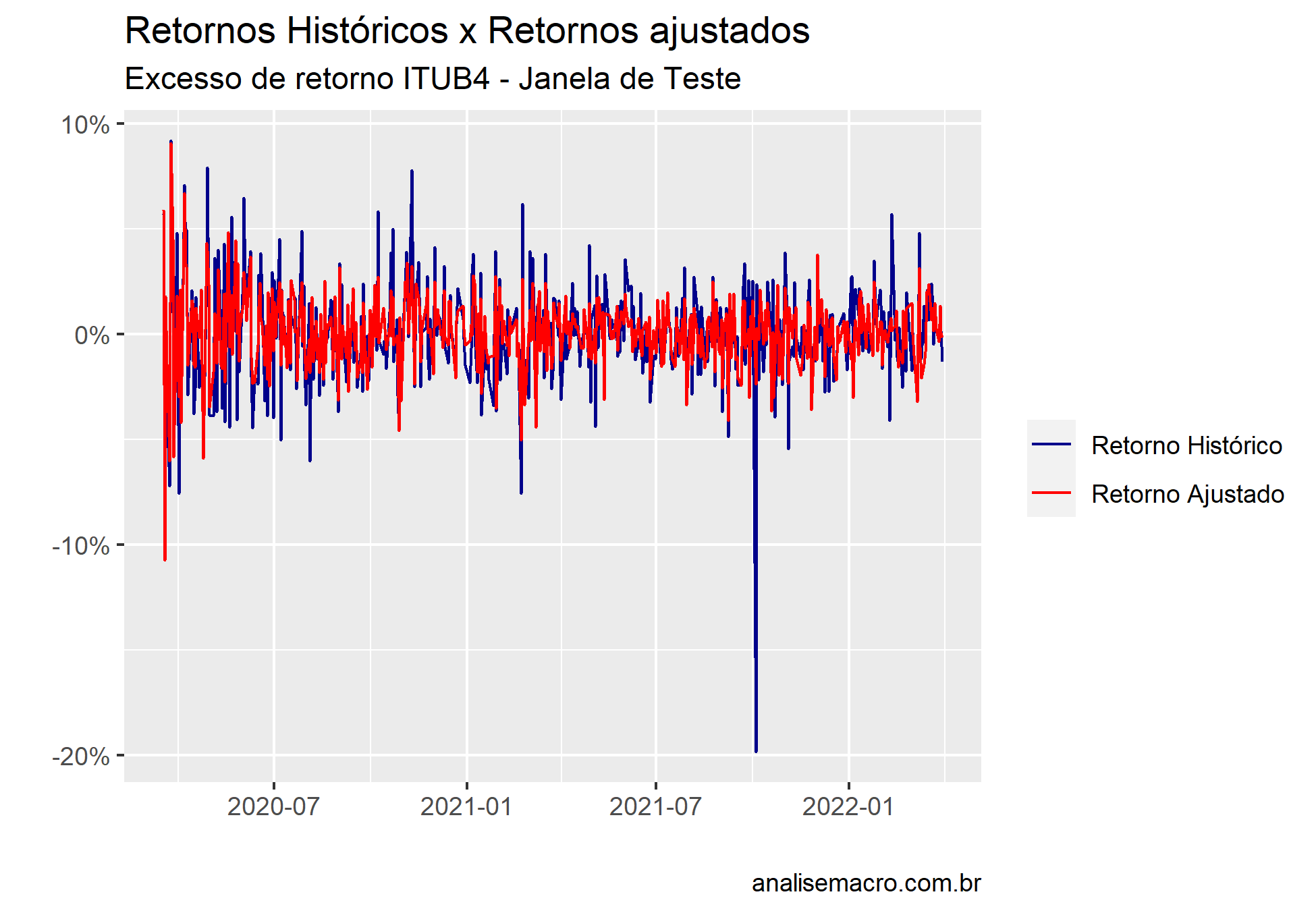
Após obter todos os dados, nosso objetivo será utilizar a série de funções do universo do Tidymodels para aplicar uma Regressão de Lasso. Primeiro iremos separar os dados de teste e treino, como forma de obter uma ideia do quão bem o modelo ajustou os dados. Selecionaremos o modelo com uma penalidade de 0.0001.
Com as amostras produzidas e o modelo em mãos, podemos rodar com a função fit(), escolhendo a fórmula do modelo e os dados utilizado (no caso a amostra de treino). Obtemos também os valores preditos pelo modelo. Por fim podemos comparar com os dados de teste.
 Quer saber mais sobre Finanças?
Quer saber mais sobre Finanças?
Veja nossas postagens realizadas sobre o assunto:
E nossos curso aplicados ao Mercado Financeiro:
Referências
Tidy Finance with R. 2022

